
The Swedish Cloud Provider
En plattform för affärskritiska tjänster och känslig data.
Certifierad leverantör enligt ISO 27001 & ISO 14001



AI-tjänster

IaaS

CaaS

PaaS
CDN

Säkerhet

Övrigt
Elastx Cloud Platform
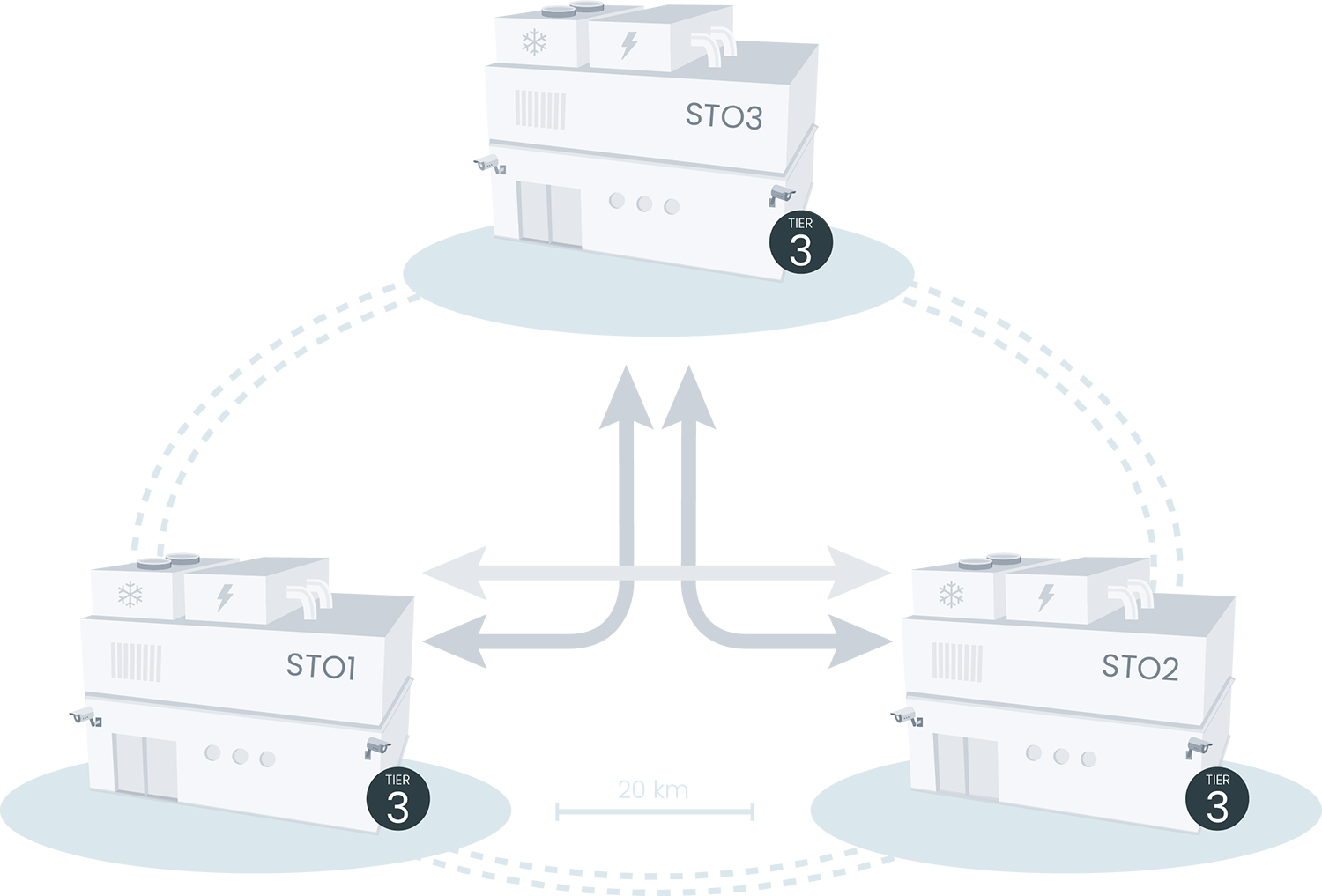
Genom våra tre geografiskt separata tillgänglighetszoner (AZ) garanterar vi hög tillgänglighet och katastrofsäkring. Säkerheten förstärks med krypterad lagring, hotskydd och DDoS-skydd.
För AI-drivna applikationer erbjuder vi GPU:er både inom OpenStack IaaS och Kubernetes CaaS. Utforska en teknologiskt robust miljö som kombinerar skalbarhet, säkerhet och avancerat AI-stöd.
Sign up
Skicka en förfrågan om ett test-konto för någon av våra tjänster genom att fylla i formuläret.
Öppna


Låt oss berätta mer
Några av våra kunder

Prorenata’s Strategic Move: Bringing Their Application Back Home
Prorenata was founded with the idea of simplifying school healthcare documentation. The rapidly growing company holds a leading position in the medtech market for developing electronic health record systems within the school sector. Through the partnership with Elastisys, a Managed Kubernetes Platform provider, and Elastx, an infrastructure provider, Prorenata can ensure that all data stays within Sweden's borders and that their service providers fall under Swedish/EU jurisdiction. They can also create the best conditions for further developing a modern cloud-native application with best-in-class security and compliance posture.
2023-10-16