
The Swedish Cloud Provider
A platform for business critical services and sensitive data.
Certified service provider according to ISO 27001 & ISO 14001



AI Services

IaaS

CaaS

PaaS
CDN

Security

Other
Elastx Cloud Platform
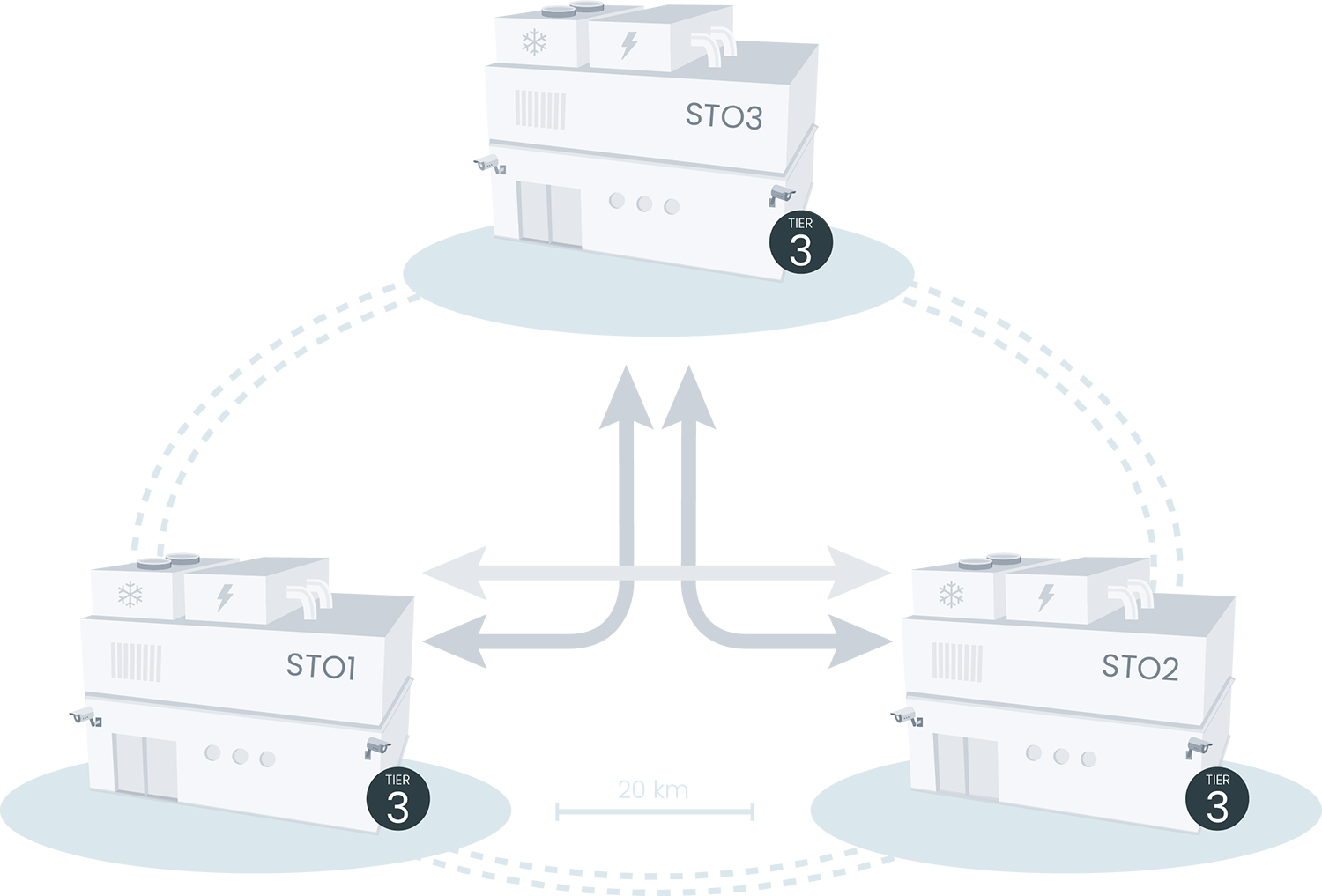
Experience unparalleled reliability and disaster protection with our three strategically located Availability Zones (AZ). Our commitment to security is evident through encrypted storage, Threat Protection, and DDoS protection.
Whether you're leveraging OpenStack IaaS or Kubernetes CaaS for AI-powered applications, we offer GPU support. Explore a technologically robust environment that combines scalability, security and advanced AI capabilities.



Get in touch
Some of our clients

Prorenata’s Strategic Move: Bringing Their Application Back Home
Prorenata was founded with the idea of simplifying school healthcare documentation. The rapidly growing company holds a leading position in the medtech market for developing electronic health record systems within the school sector. Through the partnership with Elastisys, a Managed Kubernetes Platform provider, and Elastx, an infrastructure provider, Prorenata can ensure that all data stays within Sweden's borders and that their service providers fall under Swedish/EU jurisdiction. They can also create the best conditions for further developing a modern cloud-native application with best-in-class security and compliance posture.
2023-10-16